从速度和精度角度的 FP8 vs INT8 的全面解析:哪个更适合你的应用需求?
及其快速实现量化功能的方法。第三部分为 Debug。随后讲解 FP8 的 Deep-Dive,并进行总结。
速度和精度
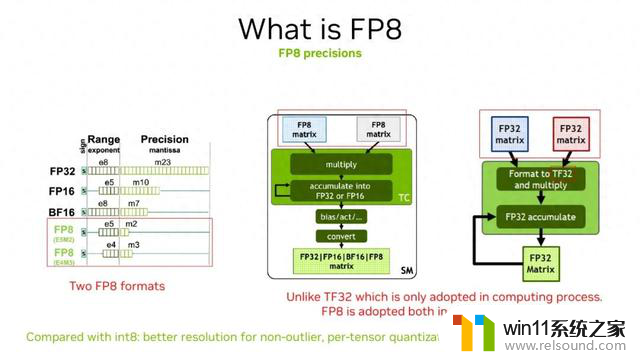
在讲解精度之前,先介绍 NVIDIA Hopper 架构上的数据类型 FP8,它有两种数据类型:E5M2 和 E4M3,在 TensorRT-LLM 中目前支持 E4M3。对 Tensor Core 硬件来说,相比于 FP32/FP16 作为输入,FP8 在数据传输上具有优势。另外,GEMM 运算可直接使用 8 比特,相对于 16 比特的 TF32 或者 FP16 更快,且支持更高累加精度以保证精度。
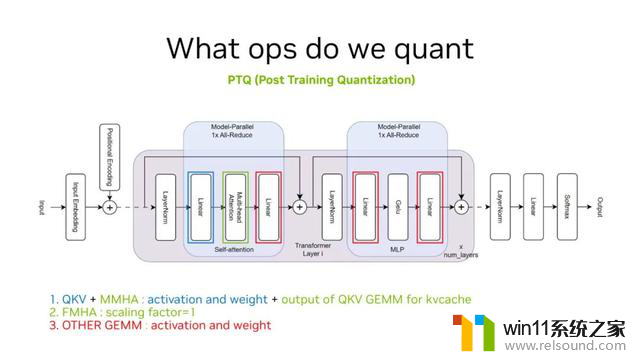
在 Perf 内容之前,需重申在做 PTQ 量化时需对哪些 OP 进行量化。以经典的 Transform 结构为例,量化主要围绕红色、蓝色和绿色框进行,涉及 4 种 GEMM 运算和 Multi-Head Attention 的量化。
PTQ 量化需计算 Scaling Factor,Multi-Head Attention 中的 GEMM 运算在 Scaling Facotr 为 1 就可以保持不错的精度(目前,TensorRT-LLM 中为了提高精度,在该部分做了 Scaling Factor 不为 1 的实现,本文内容是以 FMHA 的 Scaling 为 1 的情况下的分析)。而蓝色和红色 GEMM 运算需进行 Scaling 计算。除此之外,我们要保存 kvcache,也可对 kvcache 进行 8bit 量化,但需进行 Scaling 计算。

计算 Scaling Factor 的方法是使用 Quantize 脚本,添加如上图所示两个参数(--qformat fp8,--kv_cache_dtype fp8)即可进行 FP8 Scaling 计算。对于 FMHA Attention 无需 Scaling,生成 Engine 使用“--use_fp8_context_fmha enable”即可快速生成 FP8、kvcache 和 GEMM 运算功能。
第三步为评估,使用 MMLU 进行估计。
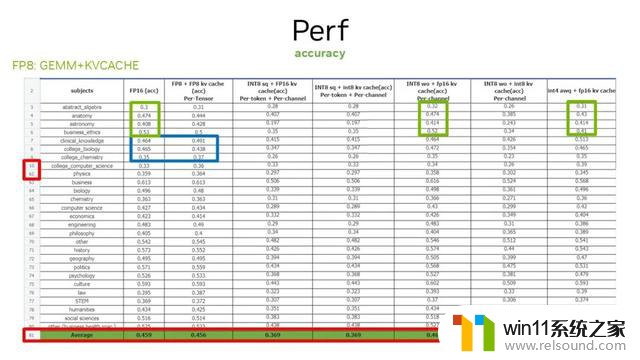
针对第三步,做精度评估时,如图所示,第一个小红框对 MMLU 78 个子数据集做了评估。因为篇幅较大,省略了中间的数据集,只展示其中的一部分。第一行代表了所做的量化方案。第一列是 baseline,GEMM 运算采用的是 FP16,在整个表中,我们对比了 Attention 以外的 4 种 GEMM 运算和对应的 kvcache 开启 FP8 情况下的精度。
首先是 FP8、INT8 weightonly + FP16 kvcache 及最后一列对应的绿色框。可以看到,除了纯 FP8 方案能够保持精度比较好的量化方式,其他的比如 INT8_sq,或者是 INT8 weightonly + INT8 kvcache 并不能保持很好的精度。
再看蓝色框部分,对比纯 FP16 和纯 FP8 方案的精度情况,以及最后一行红色框展示了平均的精度比较。
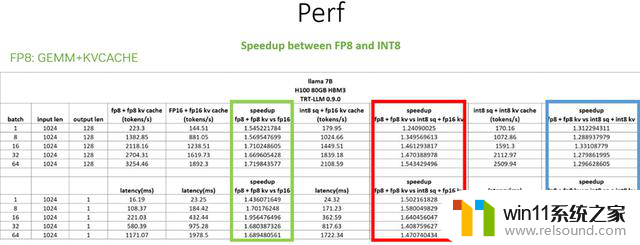
我们再看看加速比,第一列对比了 FP8 和 FP16,性能提升 1.5~1.7 倍。另外两种方式的加速比都比较不错,但是仍然没有 FP8 高。采用 INT8 sq 或者 INT8 sq + INT8 kvcache 对于精度的保持可能并不会太好。因此,我们优先推荐纯 FP8 的方案。
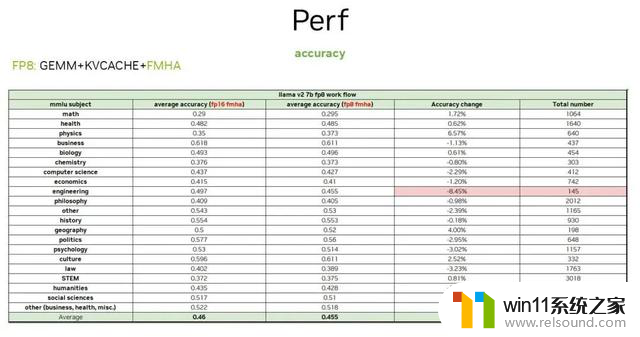
这里还测试了 GEMM + kvcache+FMHA 方案。当对 FMHA 进行 FP8 GEMM 运算 enable 时,对比纯 FP8 与 FP16 FMHA 和 FP8 FMHA 这两种方式的精度,采用纯 FP8 方案,当开启 FMHA 时,它的精度保持也是比较高的。
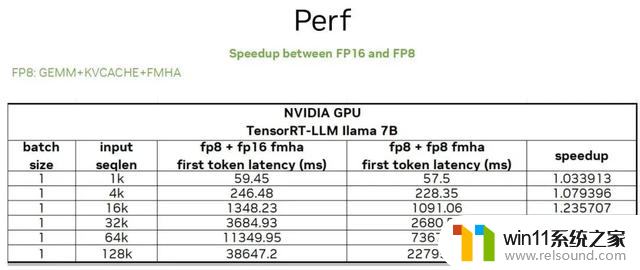
GEMM + kvcache + FMHA 对应的性能:因为开启 FMHA 的 FP8 仅是针对首 token 的优化,首 token 的计算一般情况是一个 computer bound 问题,结果如上图所示。我们在某款 GPU 上测试了 Llama2 7B 模型,input sequence 越大,开启 FMHA 的 FP8,带来的加速比越来越明显。
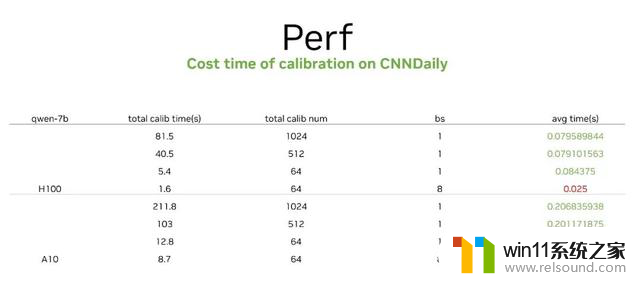
再来看下做量化的耗时情况,我们在 CNNDaily 数据集上做了测试。在这个数据集中,我们首先推荐用 512 的数据量,就可以很好的完成 FP8 保持精度的 calibration,其概耗时是 40 毫秒。这是在另一款 GPU 上做的测试,如果显存比较大,我们可以让 Batch size 变大一点,这时 calibration 的时间可以变成秒级。
量化工具 AMMO/Modelopt

接下来介绍下量化工具 AMMO,它的最新的名字是 Modelopt。FP8 PTQ 量化的方式,可以总结为三个步骤:
第一步,Calibrate pytorch model
第二步,生成 model_config
第三步,生成 engine
其中:
第一步最重要的 API 是 Quantized API,通过 Quantized API 可以生成 Scaling 的计算过程。关于这个过程,我们可以传入一个模型,设置量化的 config,比如设置成 FP8。最后,准备好需要的 calibrate 数据。

第二步主要是帮助我们生成一个 Json 文件和一组 weight 文件。Json 文件主要存储模型结构或者元数据。在 weight 文件中,group 的大小主要受 Tensor Parallelism 和 Pipeline Parallelism 影响,weight 则主要用来存储对应的参数。这步最重要的是 API,直接调用一个 API,就可以转成 model config,方便 TensorRT 生成 engine 时使用。

第三步也是通过一个 API 就可以完成,也就是加载上一步的 model config,直接生成 engine 结果。在这过程中,有一些隐藏的参数,比如训练的模型 TP/PP 比较大或者并行比较,在推理时,可以通过 API 让 TP/PP 变小。图中是我们用 Modelopt 工具做 PTQ 量化时,一些简单的 API。
如何 Debug?

在使用过程中,如果遇到问题,该如何 debug?具体的 debug 过程如下:
第一步,找到想要输出的 tensor 做注册,这里的注册通过一个 API 就可以完成。
第二步,build engine。
第三步,直接打开 debug model 进行打印即可。
如上图所示,展示了一个简单的 debug 过程。

另外,debug 可能会遇到一些经验性问题:
Attention 输出不对时,可以查看 attention 使用的 plugin 的参数,设置的是否正确。
Deep Dive
接下来,对 FP8 的 workloads 进行 deep dive,看模型什么地方用了 FP8,以及采用 FP8 之后的具体收益和为什么要这么用。最后介绍用 FP8 build 出的 engine 中 Scaling factor 和 tensor core 是怎么调用的。让大家了解 FP8 的底层原理,进而放心的去使用。
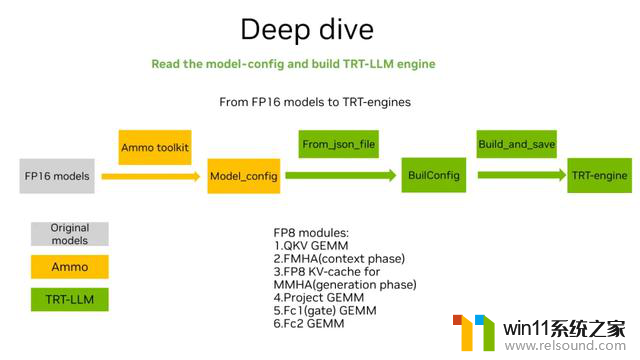
接下来介绍下从 FP16 模型 build FP8 Tensor-LLM engine 的过程。图中黄色部分代表通过 Modelopt toolkit 做 FP8 的权值转换,存出 Model_config,再通过 TensorRT-LLM 中的 From_json_file 和 Build_and_save 组件,将 Model_config 转成 TensorRT-engine。
在这个过程中,大模型通常会有 6 个部分用到 FP8。其中模块 1,4,5,6 为矩阵乘,2 是 FMHA,主要是 context phase 中的 batch GEMM 会用到 FP8。3 是 MMHA 中的 kvcache 会用 FP8 来存储,以节省显存。
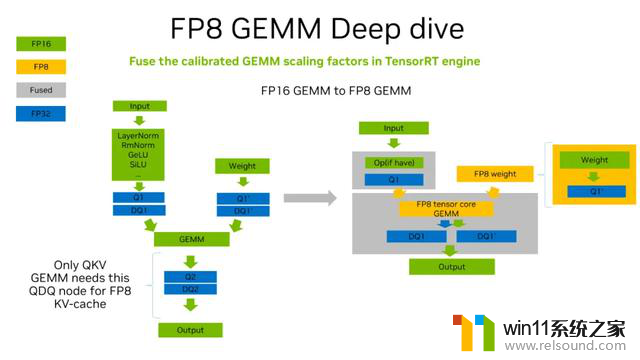
上图展示了从 FP16 矩阵乘变成 FP8 矩阵乘的过程:绿色代表 FP16 精度,黄色代表 FP8 精度,蓝色是 FP32 精度,灰色代表融合的过程。
我们刚开始拿到的是 FP16 的矩阵乘,针对这个矩阵乘的 Input 和 Weight 插入 QDQ 节点。对于 Output,如果使用 FP8 的 kvcache,也需要在 QKV GEMM 后面插入 QDQ 节点。如果不做 FP8 的 kvcache,或者矩阵乘是 QKV 之外的矩阵乘,由于 GEMM 的输出是 half 型数据,因此不需要插入 QDQ 节点。
当把 QDQ 节点都插好之后,类似 TensorRT 的流程做 calibration,使用量化校准数据集作为模型的输入,对每一个 activation 的 A-max 值做统计。我们并不是直接把 FP16 的数据 cast 成 FP8,而是通过一个量化的过程来完成。这里借助 Modelopt 工具中的 QDQ 来计算量化参数,也叫 Scaling Factor。有了 Scaling Factor,可以把左侧插完 QDQ 的计算过程转换成右侧的计算过程。
其中输入部分还是一个浮点的输入,Quantized 节点可以把输入量化成 FP8,在量化的过程中会尽可能与其他算子融合以减少数据传输。另外,权重矩阵用 weight 跟 Quantized scaling factor 乘完之后,存成一个 FP8 的值在显存中。当计算矩阵乘时,可以把 FP8 weight load 进来,再把量化之后的 input 用 FP8 的 tensor core 进行计算。这里 FP8 只有 tensor core 支持,CUDA core 是没有 FP8 的。用 FP8 tensor core 计算完之后,再做一个反量化,得出 FP16 的值。当然,输出值的类型是根据实际需要来配置的,也可以是其他的数据类型。
在国内能买到的支持 FP8 的 H20 GPU 中,INT8 和 FP8 的算力峰值都是一样的,都是 296 tflops。但实测中,FP8 用 Plug-in 或者用 TensorRT 融合的 myelin graph 运算,都会发现 FP8 比 INT8 快。这是因为 FP8 的计算是根据 Hopper 硬件的一些特性来做的计算。但是 INT8 很多的计算没有参考最新 Hopper 的架构。所以,软件优先级的问题也导致 FP8 矩阵乘的运算比 INT8 要快。当后续软件层面也会优化 INT8,这个 Gap 将不存在。
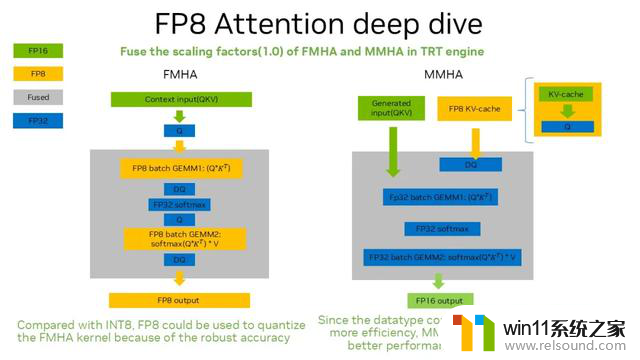
除了矩阵乘,Attention 部分也可以借助 FP8 做运算。主要有两个:
借助 NVIDIA NCU 工具,对比在未打开 XQA 情况下的 MMHA。图中蓝色代表 FP8 KV-cache,绿色代表 INT8 KV-cache。可以看到,INT8 的 MMHA kernel 在 XU pipe 上的利用率非常高,也就是所有的 kernel 运算,都会卡在这个地方,产生较高的瓶颈。(这里的 XU 是做 INT8 数值转换用到的一个 pipe。)
FP8 主要用 ALU 和 FMA,bound 情况好于 INT8。所以,FP8 KV-cache 在数值转换的 bound 程度相比 INT8 KV-cache 轻,所以 FP8 KV-cache MMHA 好于 INT8 KV-cache MMHA。
以上就是 FP8 在模型中的应用场景、优势以及使用原因的简要总结和介绍。